Share
-

-

-

-

-


AI×プライバシーテックの新境地 「統計合成データ」実
AIの急速な普及により、企業は生活者の行動予測や個別最適化されたサービス提供において、より精緻なデータ活用を求められている。しかし、高精度なAI分析に必要な詳細な個人データの活用と、プライバシー保護の両立は現代企業にとって最も重要な課題の一つ。
博報堂DYホールディングスは、プライバシーDXを推進するAcompanyと共同で、この課題解決に向けた取り組みを実施した。統計データから“擬人化”したパーソナルデータを生成する「統計合成データ」技術の実証実験により、生活者のプライバシーを完全に保護しながら、個人の嗜好をAIで精密に分析することを可能にしたのである。
本記事ではAcompanyとの実証実験の要点を当社の視点からお届けする。
AIとプライバシーの根本的なジレンマ
生成AIの登場により、AI活用の可能性は飛躍的に広がった。従来のAIが人間によって整理されたデータの枠組み内で分析を行っていたのに対し、生成AIはデータを柔軟に解釈し、非構造化データも含めた幅広い情報を処理できるようになったからである。
しかし、企業が本当に求めているのは汎用的な知識を持つAIではなく、自社の業務や顧客を深く理解した「あなたのことを知っているAI」である。そのためには企業の機密データや顧客の個人データをAIに学習させる必要があるが、ここでデータ活用とデータ保護の深刻なトレードオフが生じる。
特に金融や医療など機密性の高いデータを扱う業界では、データをクラウドに上げることができないという制約が、AI活用の「ノックアウトファクター(許容できない条件)」となっているのが現状である。
プライバシーテックが切り拓く新たな道
この根本的なジレンマを解決するのが「プライバシーテック」である。個人のプライバシーを保護するための技術群の総称で、データを暗号化したまま高度な分析が可能な「秘密計算」や、元のデータから類似データを生成する「合成データ」などが含まれる。
Appleの「Apple Intelligence」は秘密計算技術の代表例である。プライバシー保護を企業価値の軸とするAppleは、端末からクラウドへデータを送る際に秘密計算を組み込むことで、データが暗号化されたまま処理されて戻ってくる仕組みを実現した。これにより、ユーザーのプライバシーを守りながらAIの高性能さを両立させている。
「統計合成データ」という革新的アプローチ
今回の実証実験で注目されたのは「合成データ」技術である。元データの特性や特徴を模倣した人工的なデータを生成する技術で、AIの第3次ブーム頃から注目されてきたが、生成AIの登場でさらに重要性が高まっている。
合成データの生成には大きく2つのアプローチがある。元データから直接機械学習モデルを学習させて合成データを生成する「機械学習直結型」と、元データを一度統計情報に変換してから合成データを生成する「統計経由型」である。
本プロジェクトでは、後者の「統計経由型」による「統計合成データ」を採用した。これは、Acompanyの技術協力を得て、実データを統計データに集約した上で、“擬人化した”パーソナルデータを生成するものである。
実証実験で証明された安全性と有用性の両立
従来、博報堂DYホールディングスでは生活者の嗜好に応じた広告配信や市場分析に統計データを活用してきた。統計データはプライバシー保護の観点では優れているが、きめ細かい生活者の傾向把握が困難で、AI技術の学習用データとしても活用しにくいという限界があった。
そこで実証実験では、博報堂DYホールディングスが保有する生活者データから「統計合成データ」を生成し、実データと比較した有用性と安全性の両面を評価した。評価には群馬大学の千田准教授(技術面)と光和総合法律事務所の渡邊弁護士(法務面)も協力した。
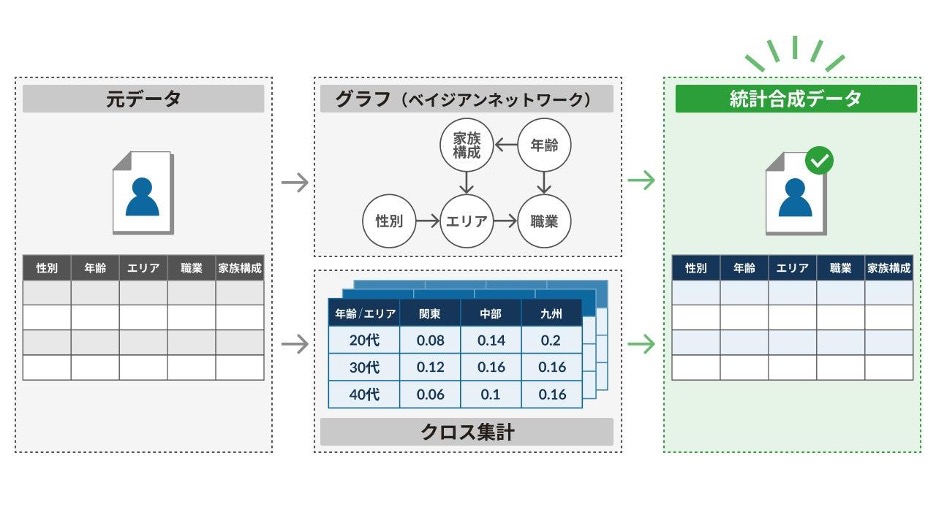 結果は予想を上回るものであった。統計経由型の合成データが元データの傾向を想像以上に保持していたのである。「ビールを飲む人の年代分布」といったクロス集計でも、大まかな傾向が維持され、実データと比べて有用性の観点で遜色ない精度を保有することが明らかになった。
結果は予想を上回るものであった。統計経由型の合成データが元データの傾向を想像以上に保持していたのである。「ビールを飲む人の年代分布」といったクロス集計でも、大まかな傾向が維持され、実データと比べて有用性の観点で遜色ない精度を保有することが明らかになった。
同時に、安全性の観点においても、差分プライバシーによって数学的に証明可能なプライバシー保証が提供されることが確認された。差分プライバシーとは、個々のデータに意図的にノイズを加えることで、数学的に安全性が証明された状態で、個人の特定リスクを低減しながら有用な統計情報を抽出できる技術である。
「パラレルワールド」のような擬似データ生成
この技術を理解するには「パラレルワールド」という例えが分かりやすい。例えばドラえもんの世界で言えば、マンガとして抽象化されたエッセンスからAIが新たにその世界観やキャラクターを再現するような感覚である。元の世界と似ているが、同一ではない擬似的な世界を作り出すのである。
単純なマスキングや乱数置換だけでは達成できない、データの安全性を担保しながらも統計的な有用性を保つという高度なバランスが実現されている。
「同意疲れ」を解決するプライバシーの自動運転
現在のプライバシー保護は「同意原則」に基づいているが、長い規約を読まずに同意ボタンを押すだけの「約款同意」のような形骸化した仕組みになっているケースが多く見られる。これは生活者にとっても企業にとっても好ましくない「同意疲れ」の状況を生み出している。
EUのGDPRでは「同意取得」よりも「適正な処理」に重点が置かれ、企業が技術的にプライバシーを保護していれば、必ずしも個別の同意だけに依存する必要はないという考え方が採用されている。
本プロジェクトで協業するAcompanyは「プライバシーの自動運転」というビジョンを掲げている。車の自動運転のように、ユーザーが特に意識しなくても技術的に保護される状態、専門知識がなくても安全に利用できる環境の実現を目指している。
日本がリードするプライバシーテック分野
実は秘密計算は日本が強みを持つ分野である。日系大手企業が先行して技術研究・実装を進めており、世界的にも高い評価を得ている。以前は「技術的に重要だが用途が限られる」と言われていたが、AI時代を迎えて具体的なユースケースが明確になってきた。
生成AIやLLM開発では米中に後れを取った日本だが、プライバシーテック領域では優位性を活かせる大きなチャンスが存在する。ただし技術だけでなく社会実装も重要で、生活者との対話や共創を通じた価値創造が不可欠である。
デジタル社会の新たなスタンダードとなる可能性
今回の実証実験は統計合成データの可能性の一部を示したに過ぎない。博報堂DYホールディングスでは今後、保有する統計データを“擬人化された”パーソナルデータによるきめ細かい分析や、AIモデルの学習データに用いることを目指している。
また両社は本実証実験を踏まえ、市場ニーズに合わせて統計合成データを利用することで、デジタルマーケティング分野における安全かつ精度の高いデータ活用を実現し、顧客体験価値と社会価値の向上に努める。
プライバシーテックがAIの可能性を広げる鍵となる時代において、データの活用と保護は表裏一体の関係にある。今回の取り組みは、安心・安全なデータ活用のエコシステム構築に向けた重要な一歩と考える。
生活者のプライバシーを完全に保護しながら、AIによる高精度な分析を実現する「統計合成データ」技術は、デジタル社会の新たなスタンダードとなる可能性を秘めている。